The REST Architectural Style
By Rishal Hurbans & Matt Van Der Westhuizen
In this era of digital technology, we find ourselves developing software that is required to be shared and utilised as far as possible in a manner that is as concise as possible. This is not a new concept, however, the need to refine and better these integrations have become more and more prevalent due to high demand for interoperability between different pieces of software.
An emerging trend is the use of RESTful APIs for both exposing data resources as well as consuming data resources from other sources. Within the development community, there exists some misunderstandings around what REST, and RESTful actually is. It is important to understand that REST is not a protocol, and it’s not a standard. REST is simply an architectural style achieved by combining a number of different well-known architectures.
Architectures
There exist commonly used architectures in most distributed web-based software. It is important to understand the purpose of these patterns and where it is applicable. This will help in understanding the principles of a RESTful architecture.
Client-Server
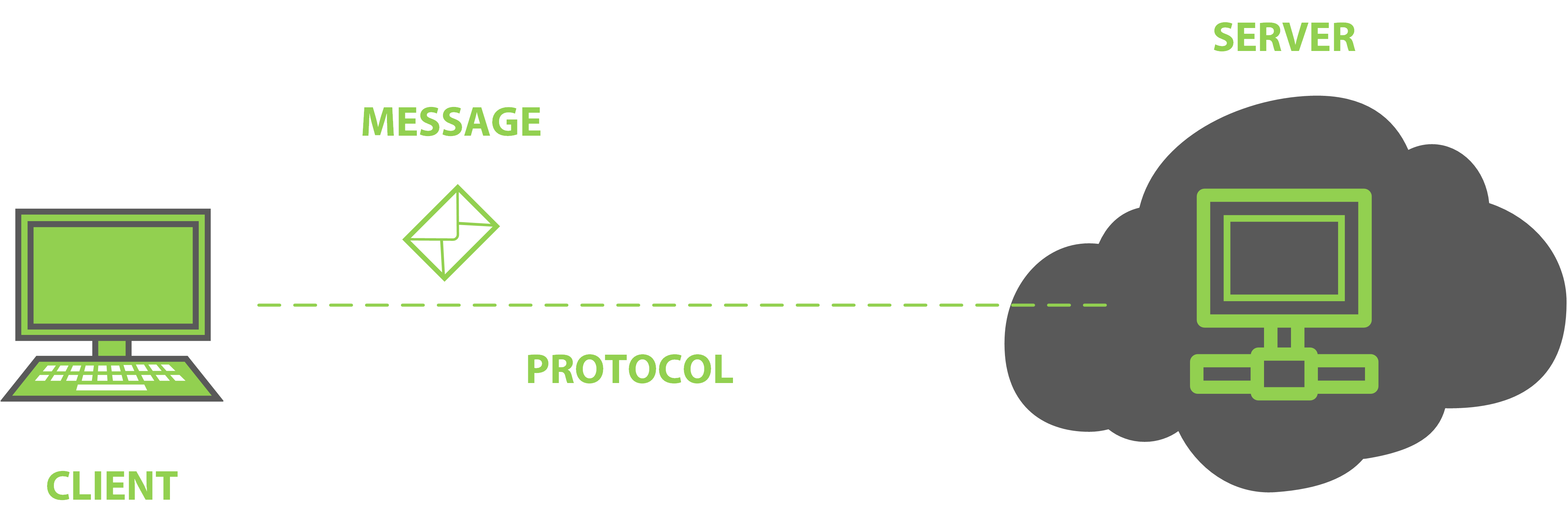
The client-server architecture is a fairly well-known and widely used architecture. Most network based applications work in this manner. The architecture consists of a server that acts as a central point that one or many clients may interact with. The idea behind a client-server architecture is that the server does the heavy lifting and orchestration required, whilst the client consumes the rich data and functionality by interacting with the server. When these computers communicate with each other, there’s a clear need for a common protocol that is understood and supported by both parties. The commonality required is the message format. Imagine the protocol being a channel of communication between two people such as speech which is common between the two, and the message format being the language that is understood between them.
Layered

The layered architecture is utilised for a number of different factors. A layered approach allows developers to separate concerns and loosely couple components that interact with each other. The advantage of this approach when implemented optimally is that layers may change independently without impacting the rest of the application. There are also cases where a layered architecture may consist of a layer that is shared across multiple other layers. An example of this is a shared domain that is utilised throughout the application. The layered architecture implies that the various layers reside within the same application container.
Tiered
The tiered architecture is very similar to the layered architecture. It consists of the same pattern and characteristics. The terminology “tier” is mapped to the terminology “layer”. The key difference between a layered architecture and a tiered architecture is that each tier resides on a different physical or virtual environment. This implies that tiers that interact with each other consist of different deployments and environments.
Stateless

A vast majority of web applications make use of a server-side managed session to keep track of a specific client. These sessions are often used for auth (authentication and authorization), keeping track of context, and storing meta data in memory that may be useful for managing the user’s activity. This makes scaling difficult as additional technologies and development is required to create session management servers in a clustered environment. The stateless architecture removes the need for the server to create and hold sessions. In a stateless architecture, the state is managed by the client via some mechanism such as tokens, header data, etc. that are passed back and forth between the client and server.
Cacheable
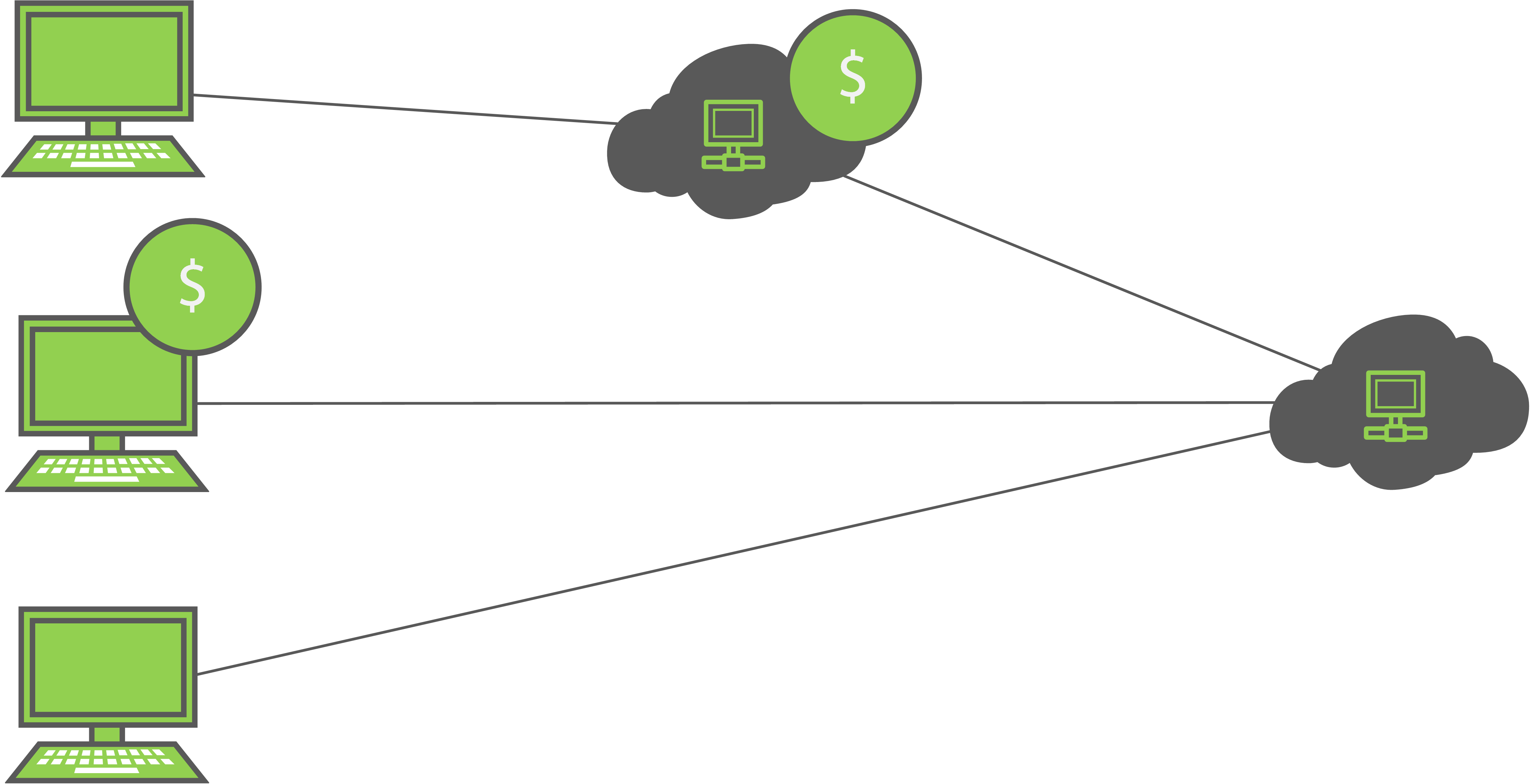
The cacheable architecture is the concept of cleverly caching data that is used often, and changed infrequently. Caching may occur in places like the client browser, and a caching server. Caching mechanisms are expected to be smart enough to serve cached data or resources until that piece of data or resource changes for the client requesting it. One of the advantages of caching is a reduced load on the network, this translates to reduction of unnecessary requests, lower data usage, and a more optimal performing application.
Uniform Interface
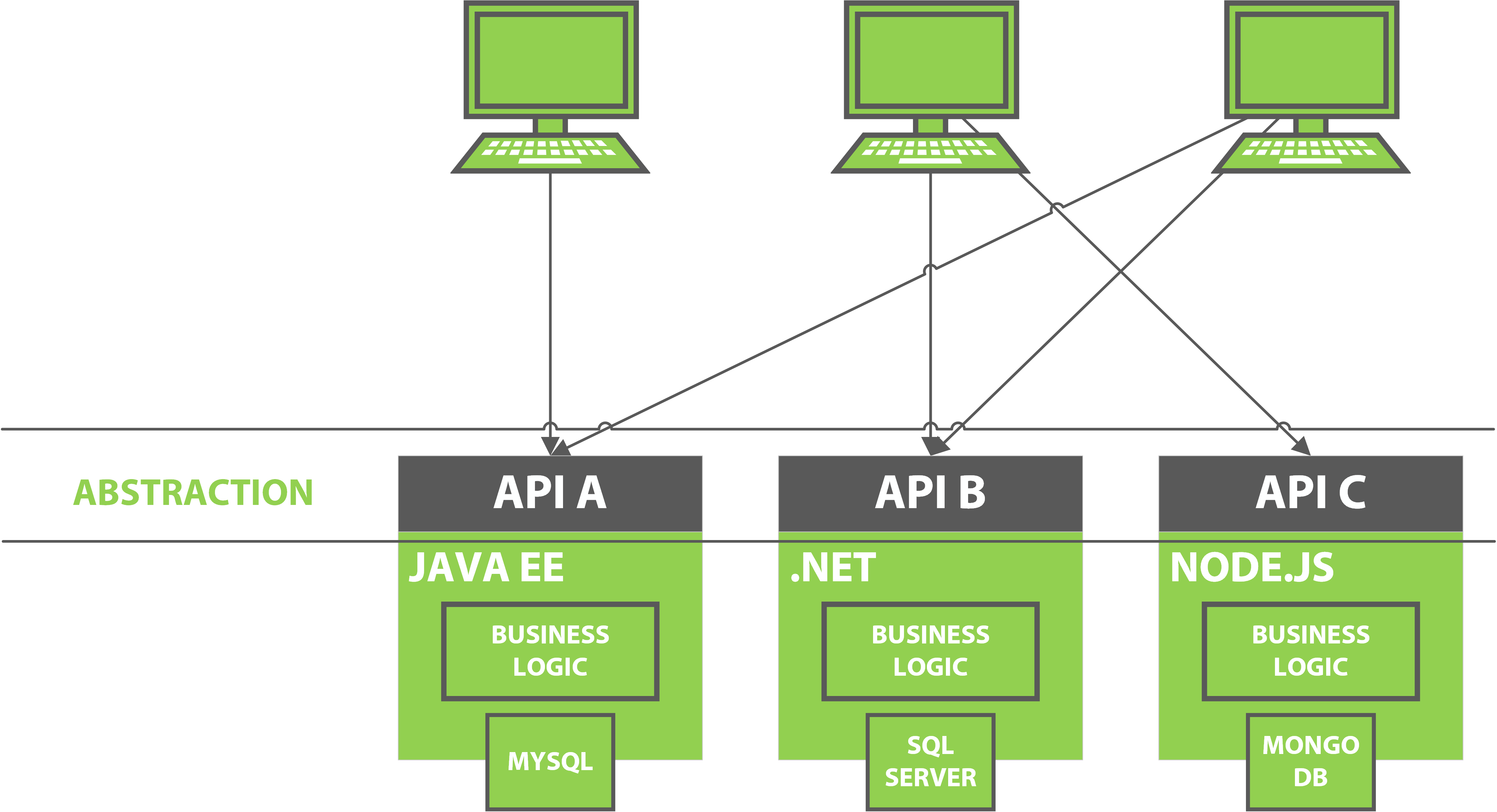
The concept of a uniform interface includes creating a standard method of interacting with a system. The uniform interface architecture also promotes abstraction of the implementation from the interface definition. This allows for clients to interact with all services in the same way, using a standard protocol and message format with a well defined set of operations.
REST Architectural Style
The REST architectural style was documented by Roy Fielding in his dissertation in the year 2000 in an effort to provide a documented architecture that could be used to guide the development and design of the modern web. The first part of this paper characterised a large number of existing architectural constraints of which the ones covered above are only a subset.
In the second part of the paper REST is defined by composing a number of these architectural constraints into a cohesive whole. The patterns used are:
- Client Server: This constraint provides separation of concerns, improves scalability and improves the portability of the interface.
- Stateless: This constraint requires that each request contains sufficient state for the server to understand what to do... this provides visibility, readability and scalability.
- Cacheable: This constraint requires that all responses from the service to its clients are explicitly labelled as cacheable or non-cacheable so that intermediary servers or components can cache responses. This improves efficiency, scalability and user-perceived performance.
- Uniform Interface: This constraint defines a simple standard for working with a REST service. It includes identification of resources by URI, manipulation of resources through representation, self-descriptive message and HATEOAS.
- Layered System: This constraint requires that a client should not be able to tell if it is connected to the end server or to an intermediary. Layered systems cause a reduction in performance, but this should be counteracted by caching.
- Code On Demand (optional): This optional constraint allows client functionality to be extended by downloading and executing code from the server.
Fundamental Concepts
Resources
A logical resource is any concept that can be addressed and referenced using a global identifier, for example a car, dog, etc. URIs are used as the global identifier when implementing REST over HTTP.
Server
A logical server where resources are located, together with any corresponding data storage features.
Client
Logical clients make requests to logical servers to perform operations on their resources.
Request & Response
The client sends a request consisting of headers and optionally a representation. The server responds with a status code, headers and optionally a representation.
Representation
The representation contains some or all information about a resources and allows modification of the resource on the server by modifying the representation and sending it back to the server.
Richardson Maturity Model
The Richardson Maturity Model was first introduced by Leonard Richardson in a 2008 conference talk as a way to judge the quality of a RESTful web API. It assumes that most of the RESTful constraints are met by using web technologies and looks at how an API uses HTTP, URIs and HyperMedia to determine its quality.
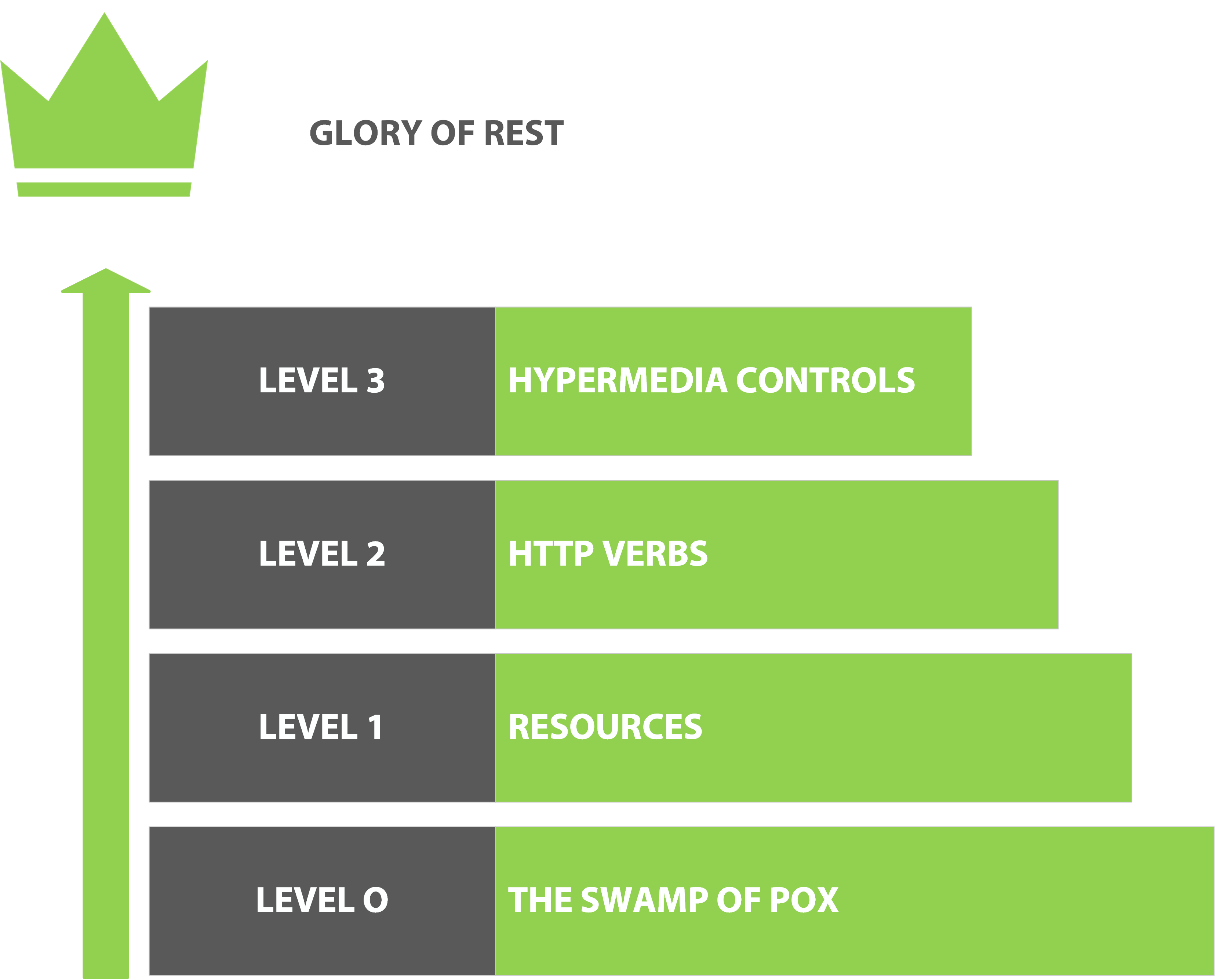
Level 0 - The swamp of POX
The swamp of Plain Old XML describes an API that is not RESTful at all. An example would be a SOAP-like web service using HTTP as transport, but not using any of the web mechanisms to its advantage. In the example below the API user will always POST a request to the same URI. What action is performed is controlled by the contents of the request.
The scenario used in the code examples in this section references the idea of having a conference where attendees have questions for presenters on a specific talk. Given this; talk and question, are resources that we would like to interact with.
Create a question
POST /createQuestionService HTTP/1.1
<createQuestion talk="Robust REST Architectures" question="Do you guys even REST?" name="HelloPieter" />
HTTP/1.1 200 OK
<talk>
<questions>
<question talk="Robust REST Architectures" question="Do you guys even REST?" username="HelloPieter" />
<question talk="Robust REST Architectures" question="What is HATEOAS?" username="CodeWarrior" />
</questions>
</talk>
What's bad about the above example is that the service is essentially a black box. Without documentation it's pretty much impossible to figure out what you can do with the service.
Level 1 - Resources
The first level of RESTfulness begins to get rid of the black box by introducing the concept of resources. Instead of having a single URI for everything our API does we have a URI for each resource that can be manipulated with the API. This simplifies interaction with the API to working with a number of smaller, simpler boxes.
List talks
# Request
POST /talks HTTP/1.1
HTTP/1.1
<talks>
</talks>
Create a talk
POST /talks/create HTTP/1.1
<talk name="Robust REST Architectures" />
HTTP/1.1 200 OK
<talk id="1" name="Robust REST Architectures">
<questions>
</questions>
</talk>
Create a question
POST /talks/1/questions/create HTTP/1.1
<question question="Do you guys even REST?" username="HelloPieter" />
HTTP/1.1 200 OK
<talk id="1" name="Robust REST Architectures">
<questions>
<question id="1" question="Do you guys even REST?" username="HelloPieter" />
</questions>
</talk>
Level 2 - HTTP Verbs
The second level of RESTfulness is attained by using HTTP verbs to implement the uniform interface constraint. That is instead of using URIs to specify what action is being taken as in the previous example, URIs only specify the resource that is being acted on and the verb specifies the operation.
List talks
GET /talks HTTP/1.1
HTTP/1.1 200 OK
<talks>
</talks>
Create a talk
POST /talks HTTP/1.1
<talk name="Robust REST Architectures" />
HTTP/1.1 200 OK
<talk id="1" name="Robust REST Architectures">
<questions>
</questions>
</talk>
Add a question
POST /talks/1/questions HTTP/1.1
<question question="Do you guys even REST?" username="HelloPieter" />
HTTP/1.1 201 Created
Location: /talks/1/questions/1
Update the question
PUT /talks/1/questions/1 HTTP/1.1
<question username="PieterMan" />
HTTP/1.1 200 OK
<question id="1" talk="1" question="Do you guys even REST?" username="PieterMan" />
View the talk
GET /talks/1 HTTP/1.1
HTTP/1.1 200 OK
<talk id="1" name="Robust REST Architectures">
<questions>
<question id="1" question="Do you guys even REST?" username="PieterMan" />
</questions>
</talk>
Delete the question
DELETE /talks/1/questions/1 HTTP/1.1
HTTP/1.1 200 OK
<talk id="1" name="Robust REST Architectures">
<questions>
<question id="1" question="Do you guys even REST?" username="PieterMan" />
</questions>
</talk>
Level 3 - HATEOAS
The acronym HATEOAS means Hypermedia As The Engine Of Application State. In essence it involves adding links to your representations to make your API explorable, similar to how links in HTML documents make web sites explorable.
List available API resources
GET /api HTTP/1.1
HTTP/1.1 200 OK
<api>
<links>
<link>
<rel>talks</rel>
<href>/api/talks</href>
</link>
<link>
<rel>questions</rel>
<href>/api/questions</href>
</link>
</links>
</api>
List all talk resources
GET /api/talks HTTP/1.1
HTTP/1.1 200 OK
<talks>
<talk>
<name>Robust REST Architectures</name>
<links>
<link>
<rel>self</rel>
<href>/api/talks/1</href>
</link>
<link>
<rel>questions</rel>
<href>/api/talks/1/questions</href>
</link>
</links>
</talk>
</talks>
The Glory Of Rest
So in summary the ideal REST API is a self-documented interactive service:
- GET /api gives a list of all resources with their links
- Following those links allow you to explore all of the resources
- Using HTTP verbs on those resource URIs allow you to perform CRUD operations
Overview of HTTP
The most popular protocol used for RESTful implementations is HTTP. HTTP (Hypertext Transfer Protocol) is an application protocol for distributed hypermedia information systems. HTTP is widely used in networked computing, it is hugely prevalent in how the internet works. This section describes the basic concepts of the protocol.
HTTP vs REST Terminology
Based on the RFC 2616 - Hypertext Transfer Protocol specification the terminology for the HTTP "method" is referred to as a "verb" in the context of the Richardson Maturity model, and similarly with HTTP's "path", "resource" is used. To elaborate, in the context of REST, a request performs an action(verb) on a resource(noun).
URLs (Universal Resource Locators)

HTTP URLs consist of several components including:
- Protocol: The protocol that the request is being made on. Typically HTTP or HTTPS. HTTPS is a secured version of HTTP. It requires a certificate to validate the authenticity of the server in relation to the domain.
- Domain: The domain includes the address of the server. Typically this is represented by a sub-domain, a domain name, and a top level domain. In the example www.prolificidea.com, www is the sub-domain, this is the default sub-domain for the world wide web. prolificidea.com is the registered domain name.
- Port: Different applications can communicate via different ports on a computer. Typically, port 80 is the default port for HTTP web application servers.
- Resource: The resource being requested by the client. This could be any media including virtual objects. An example is the /user resource gives the client data about users.
- Query: Queries are used to provide parameters for the resource being requested. An example is the /user?name=bob specifies that the client wants a user with the name "bob".
Verbs
HTTP provides several well known, widely used verbs for operations on resources, including:
- GET: Read data or resources. This verb should never be used to modify data.
- POST: Create data or resource. This verb should be used to create new data.
- PUT: Update data or resources. This verb should work on existing resources. The same PUT request should be able to be repeated with the same end result.
- DELETE: Delete data or resources. Similarly to PUT, a DELETE request should be able to be repeated with the same end result.
HTTP provides operations that are less known, but still useful:
- PATCH: Patch is used to update data or resources similarly to PUT. The difference is that PATCH requests should be used to update parts of a resource instead of updating a resource in its entirety. PATCH reduces the need to update complete objects by updating only the properties that require an update.
- HEAD: Head is similar to GET requests, however, the request should not contain a body. This request is useful to validate data or resources.
- TRACE: Trace invokes a remote, application-layer, loop-back. The TRACE request reflects the message that the final recipient server receives. This is useful to determine the final message after a request is proxied along a chain of servers. The TRACE request is useful for diagnostics on applications.
Status Codes
- 1xx: Information. The request was received by the server, continue processing.
- 2xx: Successful. The request was received, understood, accepted, and processed by the server.
- 3xx: Redirection. Additional action is required to complete the request.
- 4xx: Client Error. There was a problem with the request received by the server.
- 5xx: Server Error. The request was received, understood, and accepted by the server, however, a server error occurred in processing the request.
Many applications tend to use the 200 OK status code for all responses to the client. In the case of errors, additional information is stored in the response message body. This should be avoided. The HTTP status codes should be leveraged and used correctly in the given context. An example being, a POST request should yield a 201 Created status code in the response rather than just a 200 OK.
HTTP/2
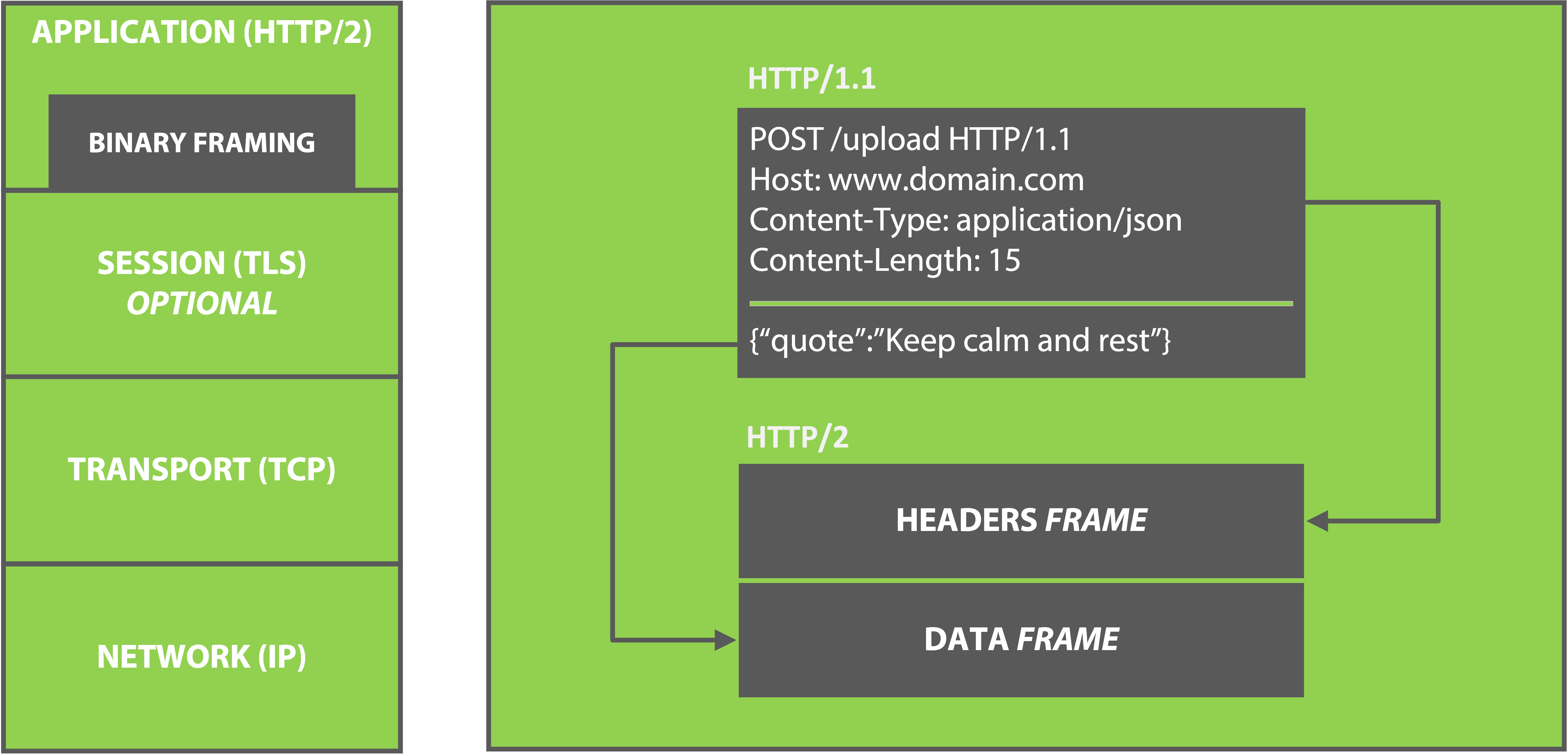
HTTP/2 is a new faster version of HTTP. The aim of HTTP/2 is to make applications quicker and more robust. HTTP/2 was spawned from Google's SPDY protocol (SPDY is not an acronym, Google just thought is sounded cool). The biggest change is the method of transporting data. Data is being transported using binary rather than using text as HTTP/1 does. Binary data is smaller than text and therefore makes it more efficiently transported over a network. Nothing changes in terms of the semantics of the protocol. The same operations and standards exist when using it. This change shouldn't affect the average web application developer. Developers that build browsers, application servers, or applications that work directly with the network layer will be impacted by the changes of HTTP/2.
Message Formats
REST is not tied to a specific message format. Initially XML was used, but in recent years JSON has become more popular as many clients are easily able to interpret JSON messages. In theory there's nothing preventing you from creating a RESTful service that uses images as representations.
Message Formats: XML
Extensible Markup Language was introduced in 1996 and forms the basis for SOAP-WS standards. Here's an example of a valid XML document:
<?xml version="1.0" encoding="UTF-8"?>
<Person>
<Name>Matt</Name>
<Surname>Van Der Westhuizen</Surname>
<Hobbies>
<Hobby>Boardgames</Hobby>
<Hobby>GameDev</Hobby>
<Hobby>Reading</Hobby>
</Hobbies>
<PhoneNumbers>
<PhoneNumber>
<Type>home</Type>
<Number>1234567890</Number>
</PhoneNumber>
<PhoneNumber>
<Type>cell</Type>
<Number>0821234567</Number>
</PhoneNumber>
</PhoneNumbers>
</Person>
As you can see the syntax is quite verbose and perhaps a bit ugly. Some of the good features of XML are that you can create customised mark-up and there is versatile standards and tooling around XML (e.g. XSD, XSLT, XPath / XQuery, etc). The main downsides are the verbosity and the complexity of the standards leading to slower more complex parsing code.
Message Formats: JSON
JavaScript Object Notation was first publicised in 2002 (based on the date the JSON.org website was launched). It supports only three primitive types:
- Scalar values
- Arrays
- Objects
Here is an example of a valid JSON document:
{
"name": "Matt",
"surname": "Van Der Westhuizen",
"hobbies": [
"Boardgames",
"GameDev",
"Reading"
],
"phoneNumbers": [
{"type": "home", "number": "1234567890"},
{"type": "cell", "number": "0821234567"}
]
}
JSON is very easy to consume on web clients thanks to being a subset of JavaScript. The limited number of concepts make parsing the data on non-web platforms quite easy to implement. JSON has less data overhead thanks to the lack of closing tags enclosing each item and no envelopes as are typically the case with SOAP services built on XML. Thanks to this simplicity there is little to no need for complex tooling.
The one downside of JSON is that it is not as rigorous as XML, but there are some efforts underway such as JSON-HAL which defines a conventional REST message format and JSON Schema which is similar to XSD for XML and can be used to define the structure of JSON resources.
Message Formats: HAL
Hypertext Application Language defines a structure for Resource representations. You still have your resource state as the root of the object as you used to, but it requires you to add a links section and specifies how to embed resources inside another resource. This diagram illustrates the concept quite nicely:
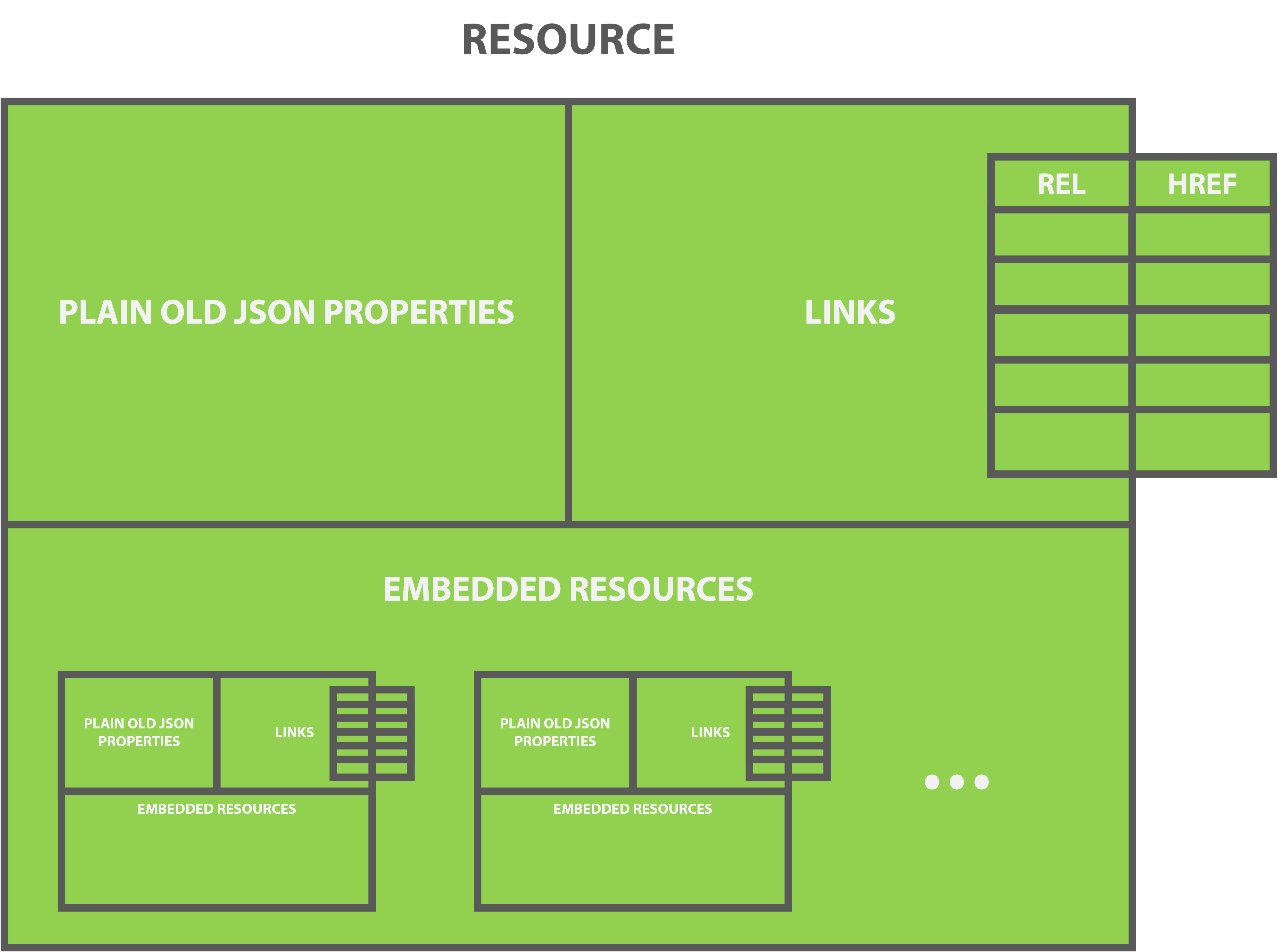
Here is an example showing a collection of users containing some embedded user resources:
{
"_links": {
"self": { "href": "/users" },
"next": { "href": "/users?page=2" },
"find": { "href": "/users{?surname}", "templated": true }
},
"_embedded": {
"users": [
{
"_links": { "self": "/users/1" },
"id": 1,
"name": "Rishal",
"surname": "Hurbans",
...
},
...
]
},
"page": 1,
"pages": 4
}
One of the benefits of HAL is that it can work with either JSON or XML, but the downside is that there is no agreed upon way to specify validation rules.
Message Formats: JSON Schema
JSON Schema is similar to XSD for XML, but only works for JSON resources. It provides a format for providing schema meta-data about resources that can be used for validation. It also has an extension for defining resource hypermedia which works similarly to HAL's _links.
Here's an example of JSON Schema for a person which would allow us to validate that person's name is a string and that they should have at least 1 hobby:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"title": "Person Schema",
"type": "object",
"properties": {
"name": {
"type": "string"
},
"hobbies": {
"type": "array",
"minItems": 1,
"items": { "type": "string"}
}
},
"required": ["name", "hobbies"]
}
Conclusion
The REST Architectural style is comprised of a combination of well known architectures. It leverages the benefits of each architecture to provide a consistent, yet flexible pattern for building interactive services. The Richardson maturity model is useful as a yardstick to determine ease of use and extensibility of your RESTful implementation. Although typical RESTful implementations operate over HTTP using JSON as a message format; one could potentially use any protocol and message format. In theory one could create an API that conforms to the principals of the REST architectural style that uses the FTP protocol with images as the message format - it's just questionable if that would be useful? Bottom line, is that the REST architectural style is a guideline, it's open to creativity (and abuse). A truly elegant RESTful API is a combination of following these guidelines as well as designing resources and interactions that solve real-world problems in a sensible way.